As datasets grow to millions of samples and models scale to billions of parameters, understanding the structure hidden within data has never been more critical.

What does your data actually look like?
High-dimensional data is inherently difficult to visualize and interpret. Techniques like t-SNE, UMAP, and h-NNE transform complex feature spaces into meaningful 2D representations, revealing clusters, outliers, and relationships that would otherwise remain hidden.
Understanding when and how to apply these methods is essential for anyone working with modern AI systems, from dataset curation to model debugging.
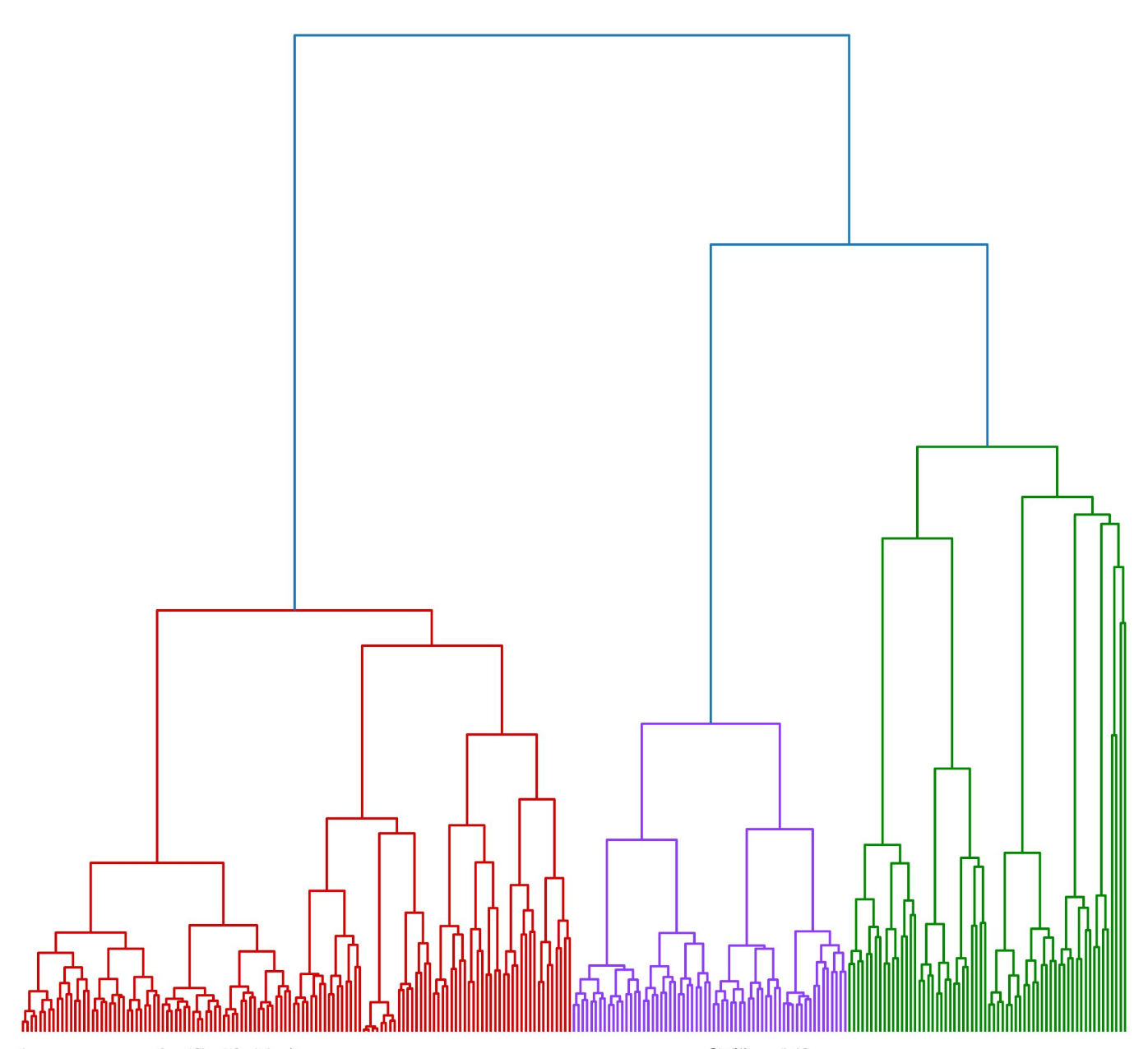
Clustering: Discovering Natural Groups
Clustering algorithms like k-Means, DBSCAN, and FINCH organize unstructured data into meaningful groups without supervision. They power knowledge discovery, data curation, and retrieval-augmented generation pipelines.
Choosing the right algorithm and understanding its assumptions can mean the difference between actionable insights and misleading artifacts.
Tutorials, Workshops, and Meetups
This event series brings together researchers, practitioners, and students to bridge the gap between theoretical advances and practical applications — from foundational algorithms to cutting-edge methods.
Whether you're a PhD student exploring embedding spaces or an industry engineer building production pipelines, our events are designed to deepen your understanding and expand your toolkit.

